Accounting Professional Training (APT), is a South African training company that provides a range of professional programs helping the students to qualify as Chartered Accountants.
Problem
Students in APT are engaged in taking exams where they analyze multiple (from 6 to 9) different business cases. Efficient and timely processing and grading of exam scripts is a unique feature of APT business.
However, large-scale quarantine measures imposed in 2020 in most countries led to the new challenge: when a student takes exam from home, it becomes almost impossible to spot and prevent plagiarism. With a typical number of students taking each exam ranging from 1000 to 2500, it is unfeasible to check all pairs of works for possible plagiarism.
This situation is not properly addressed by existing anti-plagiarism solutions, that are focusing on finding parts taken from published sources, for example from scholarly articles, or web resources such as Wikipedia, but not on detecting plagiarism during an online exam. Moreover, with texts often containing ‘natural’ identical parts, for example standard conversational formulas, accounting jargon phrases, and citations from laws, the mission is becoming nearly impossible.
Solution implementation
To address the APT issue, Silk Data experts implemented an antiplagiarism solution based on the document processing and analysis platform. The solution consisted of a custom preprocessing of PDF formats used by APT, text comparison engine, and visualization of results for analysis.
To find similar texts, two algorithms were selected: search for verbatim copied pieces of text, based on finding common triplets present in texts, and ‘vector’ or semantic representation of text meaning, aimed on detection of paraphrases. The latter representation is based on Silk Data proprietary Semantic map technology.
Because the exam scripts may contain legitimate common pieces, the final solution acts more like a filter: it locates suspicious pairs of documents that reach a specified similarity threshold. After such filtering, it only takes a couple of hours for a human professional to manually review 20-30 pairs of documents.
Another complication faced during implementing the plagiarism detection system is that different students produce varying document length (typically, from 20 to 55 pages), but the plagiarized parts can be just about a page to be decisive for APT’s evaluation. To address this challenge, the comparison of scripts was performed on pieces of documents: pages for verbatim plagiarism and semantically uniform parts as determined by the custom AI model.
The last major feature of the solution is visualization of results for easier analysis. Different comparison approaches lead to different visualization methods accordingly. Analysis of verbatim plagiarism uses highlighting of common passages of text (is similar to what text processing suites use to compare documents):

Paraphrase detection shows the most similar words (not necessary present in text (see picture below).
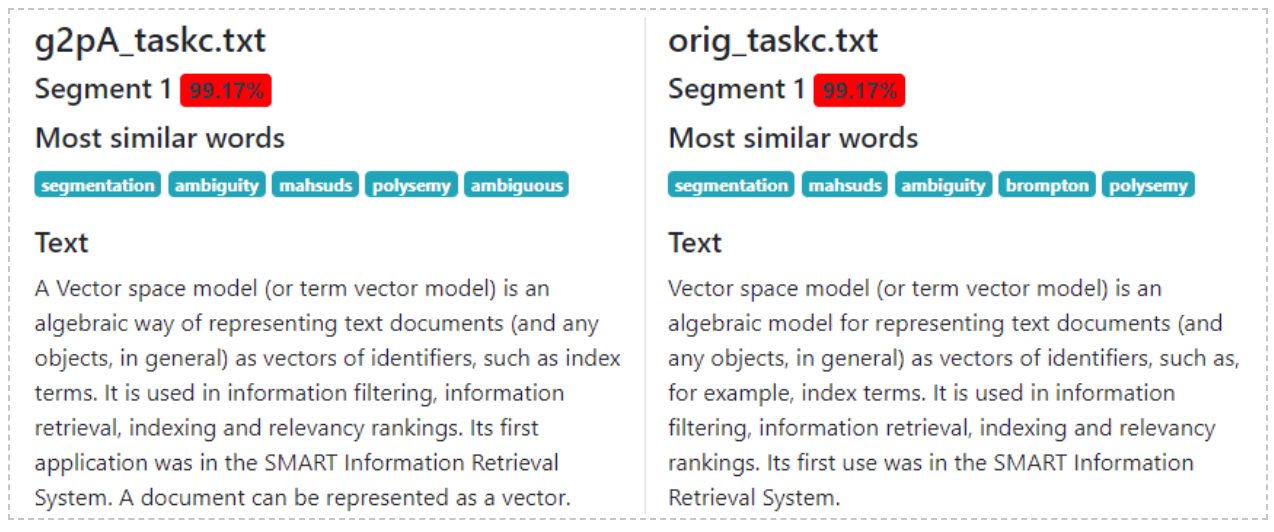
(these examples are based on A Corpus of Plagiarised Short Answers, as collected by team of researchers from the University of Sheffield, see http://ir.shef.ac.uk/cloughie/resources/plagiarism_corpus.html)
Outcome
As a result of APT and Silk Data collaboration, APT was able to minimize the involvement of their instructors. Without automated text comparison provided by Silk Data, such analysis was impossible within reasonable timeframes.
The implemented solution can be easily implemented for similar cases in education and professional training. Silk Data technology is mainly task- and language-independent, therefore adapting it to other use-cases will only require support of specific document formats.